
I participated in the Rinha de backend (pt-BR) or “Backend Rooster Fight” in English challenge and I was super excited to see the results of my super hacky and performant solution.
The results were scheduled to be published at 21:00 BRT (2 AM CEST my local time). So I stayed up til later that night grabbed popcorn, and waited for the results.
Well, I wish I hadn’t waited…
TL;DR; My solution didn’t run on the official test server because I built the docker image to
linux/arm64instead oflinux/amd64🤦🤦🤦 . I fixed the issue and ran the same tests afterward and I reached ~50% of points of the winner, mainly because in my solution I didn’t tolerate any risk of losing writes. Checkout my repository flavio1110/rinha-de-backend with my solution.
What was the Rinha de Backend?
Before we get into the details, a brief explanation of what was the challenge.
From July 28th to August 25th, the Backend Fight was held, a tournament in which the API that supported the most load during a stress test would be the winner. Participants had to implement an API with endpoints to create, query and search for ‘people’ (a kind of CRUD without UPDATE and DELETE). In the tournament, participants still had to deal with CPU and memory restrictions – each participant had to deliver the API in docker-compose format and could only use 1.5 CPU units and 3GB of memory. More details on technical aspects can be found in the instructions) – (translated from its repository in English).
On top of the description above, some things important to highlight are:
- You can write your API with any language or framework, as long as you can build a docker image out of it
- The solution has to run two instances of the API in parallel.
- The requests will be balanced as you wish between these instances via Nginx.
- You have to use one of the following data stores: MySQL, PostgreSQL, or MongoDB.
It was a super fun, informal, practical, and a very good opportunity to exercise and learn new things.
How the winners were determined?
To make the comparison easier and fun, the single parameter used to determine the winner of the challenge was the number of people inserted into the database.
How did I do?

I didn’t. I was disqualified because the container with my APIs didn’t start. Therefore I got nothing. 🤦🤦🤦
Wrong platform?
Yes, that’s true. My solution didn’t even run because it failed to start the APIs. I built the images for linux/arm64 instead of linux/amd64.
It was a mistake on my end, and it made me super disappointed. I ran the tests on the CI pipelines, and it gave me confidence the image was properly built and I didn’t double-check the requirements. Shame on me.
Well, I was disqualified but I was curious to see how it would perform on a server with the same configuration as the one used for the official tests. So, I fixed the platform of the image, spun up an EC2 with the same configuration, and finally ran the tests. The results were a bit disappointing compared to the TOP 10.
How did I approach the problem?
I had two constraints in mind while designing and building:
- It has to work – each endpoint has to do what it is supposed to do.
- Keep things as simple as possible.
Each of these points brought a few tradeoffs that ended up limiting the overall performance of the solution.
You can check my solution on flavio1110/rinha-de-backend. It’s built with Go and PostgreSQL.
Given many APIs were performing super well, a few days before the last day of the challenge, the load for the stress test was doubled, and it had a massive impact on the performance of my API. You can check the comparison below:
Before…
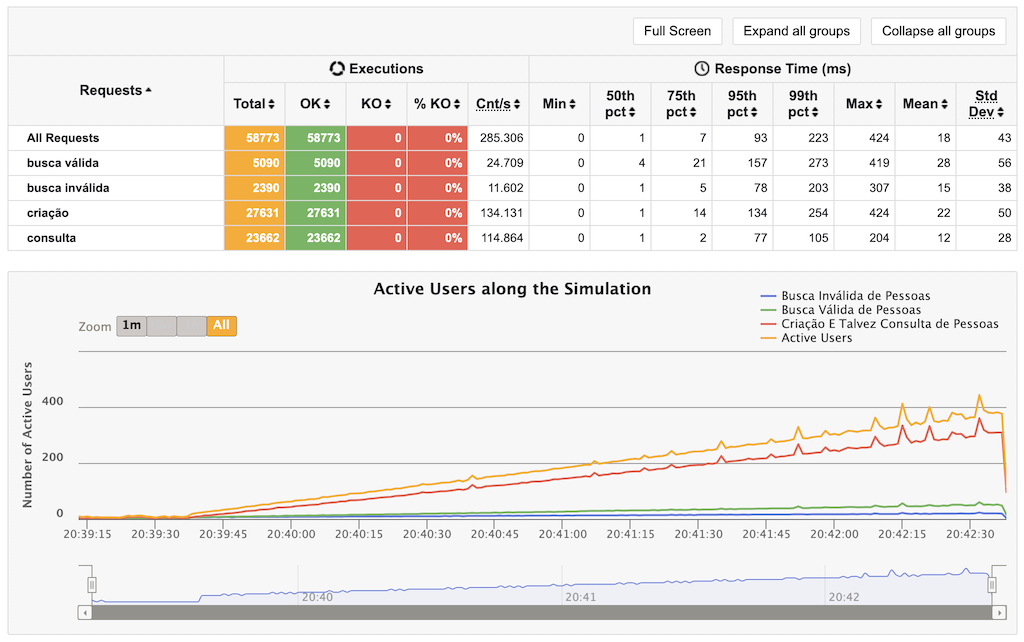
After…
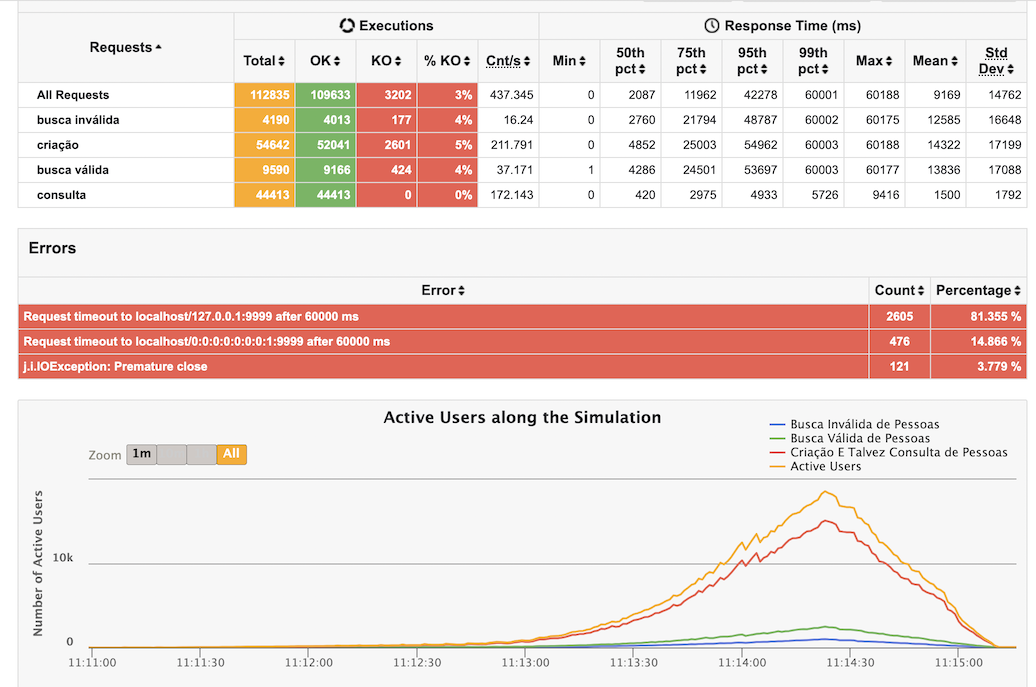
What were the bottlenecks?
The inserts were the bottleneck. Because I didn’t tolerate the risk of losing writes and wanted to keep it simple, I missed the opportunity to introduce a distributed mechanism to validate the data before trying to insert it into the database and perform the inserts in batch.
Validating the uniqueness of a field Apelido (Nickname)
On my designed solution, without a distributed cache, it was not possible to perform without the DB in 100% of the cases.
I had an in-memory cache, but if the nickname wasn’t there because it wasn’t there because the entry was inserted via the other instance, that request would reach the DB, occupy a connection, take resources, etc.
Introducing a distributed cache like Redis would enable me to add and check the entry in a single place. As a result, we could decrease the memory necessary to run the APIs and move to the cache.
Batching inserts
I inserted each entry per a valid request because I didn’t want to risk losing valid writes in case there was any error between the construction of the batch and its execution.
This was a huge problem because it used too many DB connections and resources, and slowed down the creation request.
Did I like it?
Despite my results, I loved the challenge! I learned quite some tricks with nginx config and some insteresting stuff like using Redis or even PostgreSQL as a “PubSub”. The interaction with the community via Twitter and Github was super nice! I also liked the fact of working with something challenging and closer to reality. Loved it!
What could I have done differently?
- Build the image using the correct platform.
- A challenge is a challenge. I should have been more flexible with the writing.
- Tweak the Nginx configuration to load balance based on fewer connections and disable logs.
- Use a distributed cache and drop the read table.
- Batch inserts.
What’s next?
Check the official results and look into the repositories of the participants. I guarantee I’ll learn something new.
Stay tuned on @rinhadebackend for the next challenges, I can’t wait for the next ones.
Other than that, I’ll apply the lessons learned to my solution and hopefully get better results. Watch flavio1110/rinha-de-backend and see how it will evolve.
This challenge is officially over, but you can still do it. Challenge accepted?